发布日期:2025-12-29 20:53 点击次数:131
代码大模型最近变天了,以前大家都盯着HumanEval这些“题库”比谁分数高,现在突然集体转向真实开发场景,连《代码智能实践指南》都开始批判“刷题式训练”,说AI该突破函数补全的局限了。
这种转型不是小打小闹,背后是技术逻辑的根本变化。
今天咱们就掰开揉碎了聊,代码大模型到底怎么从“做题家”变成“工程助手”,普通开发者又该怎么适应这波变革。
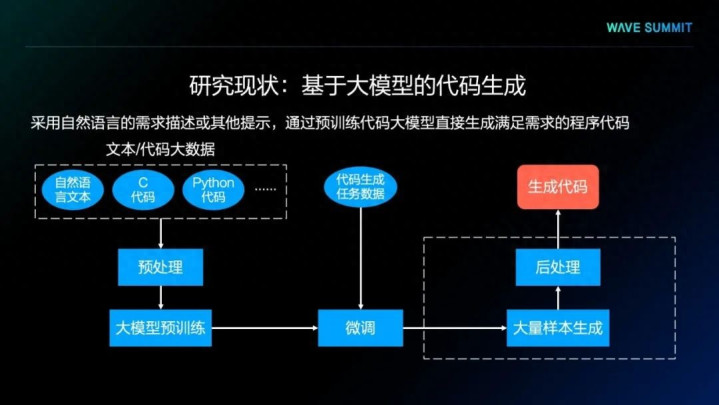
代码大模型的进化锚点从技术突破到工程落地
最近业内都在聊DeepSeek-R1这个模型,它最绝的不是刷分多高,而是学会了“自我纠错”。
输出代码后自动编译、跑单元测试,用结果当奖励信号优化自己,这不就是开发者日常debug的思路吗?
传统AI写代码总被吐槽“输出不可控”,写出来的东西看着对,一跑就报错。
现在把CI/CD那套流程和强化学习结合,AI自己就能验证对错,靠谱多了。

以前AI顶多帮你补几行代码,现在不一样了,SWEAgents这种智能体能直接操作Git仓库,改配置、跑测试,整个软件开发生命周期都能介入。
GitHubCopilotX的AutoFix功能已经能自动修复依赖冲突,这可不是简单的函数补全了。
衡量AI的指标也变了,以前比Pass@1,现在看能不能修复仓库级bug,毕竟真实开发里,没人只写独立函数,都是在几十万行代码里改东西。
以前搞模型总觉得数据越多越好,现在发现代码数据不一样,清洗数据、抓执行反馈、优化长上下文理解,这些基本功比堆数据量更重要。

代码有AST这种结构化表示,模型能直接看懂逻辑,噪声少多了,质量自然上去了。
代码大模型能往工程场景渗透,不是偶然。
编程语言有明确的语法规则,逻辑对错能验证,这种“确定性”是AI最擅长的。
软件工程又能拆成需求分析、模块开发、测试部署这些小任务,正好适合AI一步步接手。

认知颠覆重新定义AI编程的三大反常识视角
以前总听人说RAG多厉害,能让AI查代码库,现在发现长上下文模型更直接,GPT-4Turbo128K上下文能塞进去整个项目代码,不用来回检索,写多文件关联代码时顺畅多了。
有专家说过度依赖索引反而会限制AI,毕竟真实开发时,开发者都是对着整个项目思考,AI也该有这种“全局视野”。
本来以为AI得像人一样聊天协作才自然,结果ChatDev那种“角色扮演”效率低得离谱。
后来才明白,AI模块该像微服务那样用API通信,暴露中间表示比如函数调用schema,比自然语言对话靠谱多了。

就像前后端协作靠接口文档,AI之间协作也得有结构化规则,不然你说“优化这段代码”,AI可能理解成加注释,完全跑偏。
现在开发都离不开IDE的可视化界面,以后可能真用不上了。
有团队预测,当AI能从需求直接动手操作文件系统、Git、Docker时,IDE会退化成结果查看工具,headlessAgent在后台把活儿全干了。
DevOps场景已经有苗头了,AI自动部署环境、分析日志、恢复故障,端到端不用人插手。
开发流程估计也会走这条路,可视化操作反而成了效率瓶颈。
警惕“应试AI”陷阱!古德哈特定律在代码大模型这儿也生效,盯着Pass@k指标训练,AI可能写出“看着能跑但维护性差”的代码,硬编码测试用例,换个场景就废。
模型记忆特性还导致基准测试“污染赛跑”,测来测去都是老题目,得建动态更新的评估体系,不然根本不知道AI真实水平。
别被Agent的“自主性”骗了,固定提示顺序的AI遇到没见过的场景就抓瞎。
上次有团队用Agent部署系统,遇到突发网络波动,AI直接卡在“等待响应”步骤,根本不会切换方案。

强化任务分解和异常处理能力,比堆功能更重要,那开发者该怎么升级能力?我觉得首先得建立“可执行反馈优先”的工作流。
写需求时先搭好单元测试框架,AI输出后马上自动验证,不行就迭代,把自己变成“AI教练”而非“代码搬运工”。
和AI协作别指望自然语言说清所有事,用APIschema、思维导图这些工具约束AI行为更靠谱。
比如你说“优化登录接口”,不如给个包含“响应时间代码库健康度也得重视起来。

现在AI爱从训练数据里抄代码,要是你代码库里有过时依赖、重复逻辑,AI可能直接搬过来,埋一堆雷。
定期评估代码质量,相当于给AI喂“干净的食材”,代码大模型的终极竞争力,从来不是单一模型多能打,而是整个工程系统能不能“适配AI”。
就像当年云计算普及,不是服务器变厉害了,是整个IT架构都为云做了改造,开发者得从“工具使用者”变成“系统架构师”,用验证体系、协作框架、数据治理这三把刷子,掌控人机协作的主导权。
毕竟AI再强,也得靠人设计规则、把控方向,以后重复劳动肯定会被AI接管,但复杂问题攻坚、创意设计这些活儿,还得靠人类工程师。
到那时,“写代码”可能不再是核心技能,“让AI高效写代码”才是真本事,这波变革,其实是给开发者腾出手来做更有价值的事。

齐鲁晚报·齐鲁壹点记者刘宗智 由贾樟柯执导的电影短片《都灵之影》(TORINOSHADOW)日前正式宣布完成拍摄,并公布剧照及工作照。 《都灵之影》于2026年2月在中国广东台山开机,之后远赴意大利都灵进行拍摄;故事讲述一位女性在从广东前往都灵探望丈夫的过程中,意外地找回了自我,也发现了电影。该片片长为32分钟,由赵涛主演,茂涛、仁科及小演员卢夕联合主演,贾樟柯、万佳欢联合编剧,梁嘉艳监制。据悉,短片中还使用了五条人乐队的一首经典歌曲。 该片由意大利都灵国家电影博物馆、贾樟柯艺术中心、“NOW...
齐鲁晚报·齐鲁壹点记者刘宗智 由贾樟柯执导的电影短片《都灵之影》(TORINOSHADOW)日前正式宣布完成拍摄,并公布剧照及工作照。 《都灵之影》于2026年2月在中国广东台山开机,之后远赴意大利都...
代码大模型最近变天了,以前大家都盯着HumanEval这些“题库”比谁分数高,现在突然集体转向真实开发场景,连《代码智能实践指南》都开始批判“刷题式训练”,说AI该突破函数补全的局限了。 这种转型不是...
原标题:揽金牌、破纪录!射击世界杯宁波站中国队打响“开门红” 射击世界杯宁波站(步手枪)9日开赛,中国队主场作战喜报频传。姚千寻/胡凯获得10米气手枪混合团体金牌,彭鑫露/盛李豪在10米气步枪混团项目...
新京报讯 据富川发布消息,近日,有关\"富川县人民医院暴力接生\"的舆情引发了网民关注,富川瑶族自治县卫生健康局对此高度重视,事情发生后即开展了调查。 经调查,2024年10月20日上午,产妇林某某在...